Video annotation services
High-quality labeled video data to train computer vision models
Comprehensive video annotation solutions

Managed Enterprise Services
We design our workflows specifically for the challenges of video data – covering scene segmentation, frame-rate and format considerations, and ontology setup for objects, actions, and events. Your dedicated project manager coordinates each phase, from pilot to scaled production, ensuring quality benchmarks are met and communication stays clear. The result is fully annotated video datasets delivered on time and ready for integration into your AI training pipeline.

Specialized Global Workforce
For tasks like multi-object tracking, keypoint annotation, lane detection, and activity recognition, we assemble domain-trained teams with relevant industry expertise – whether that’s automotive, retail, manufacturing, or security. With access to a network of over 7 million contributors in 150+ countries and 1,000+ language locales, we capture cultural context and environmental nuances, from signage and seasonal changes to region-specific behaviors.

Rigorous Multi-Layer QA
Our multi-tier review process is tailored for video, including frame-level checks, sequence-wide consistency reviews, and validation against gold-standard clips. This safeguards temporal accuracy and reduces drift over long sequences. When needed, projects can be completed inside one of our five ISO 27001-certified secure facilities, with SOC 2, GDPR, and HIPAA-aligned processes to protect sensitive content.

LXT for video annotation
With LXT, you can quickly build a reliable data pipeline to power your computer vision solutions and focus your time on building the technologies of the future. The combination of our video annotation platform, managed crowd, and quality methodologies delivers the high-quality data you need so you can build more accurate AI models and accelerate your time to market.
Every client engagement is customized to fit the needs of your specific use case, and our quality guarantee ensures that our clients receive training data that meets or exceeds quality expectations.
Our video annotation services include:
Dialog and conversation tracking

Video classification

Video captioning
Video annotation related services:

Video transcription
Translate the audio from videos into text for both short-form and long form videos to improve video captioning capabilities, search results and more. Support for various video types including YouTube and TikTok.
Video evaluation
Review and assess the quality of video content and annotations to ensure accuracy and consistency for AI model training.



Secure video annotation services
Video content often contains proprietary or sensitive information, so we apply a security framework built to safeguard visual data from ingestion to delivery. For projects requiring maximum protection, annotation can be performed in our access-controlled facilities under direct supervision.
All secure sites are ISO 27001 certified and PCI DSS compliant, with processes aligned to SOC 2, GDPR, and HIPAA standards – ensuring your video data is handled with the highest level of confidentiality and compliance.
Case studies on video annotations

Top industry uses of video annotation
Video annotation supports a wide range of computer vision applications, enabling AI models to interpret and respond to dynamic, real-world environments with greater accuracy. Organizations across industries use it to improve efficiency, enhance safety, and unlock new AI-driven capabilities.
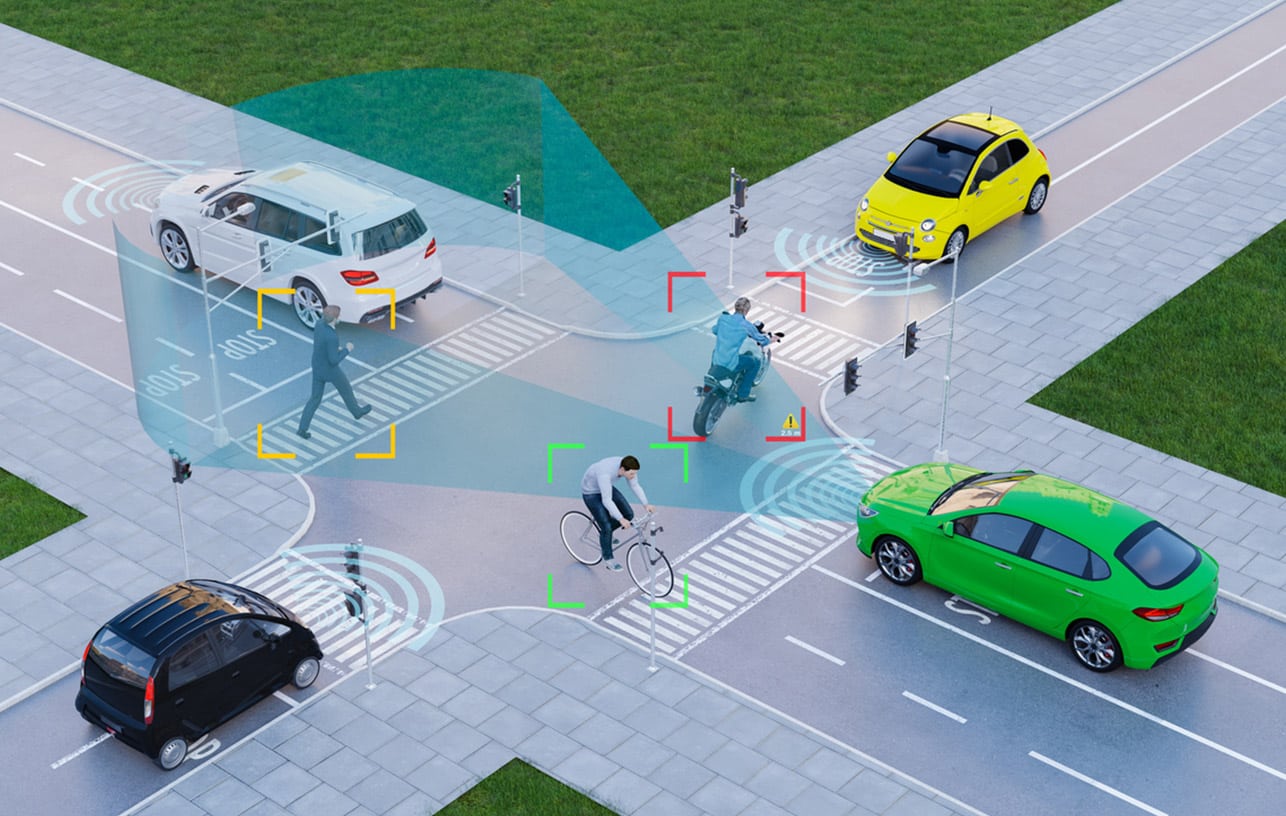
Autonomous vehicles
Train vehicle perception systems to detect pedestrians, other vehicles, lane markings, and traffic signals in real time.

Retail & eCommerce
Support in-store analytics, customer journey mapping, and real-time inventory tracking to optimize store layouts and merchandising.

Manufacturing
Enable automated defect detection, assembly verification, and safety compliance monitoring on production lines.

Security & surveillance
Enhance threat detection, crowd analysis, and suspicious activity recognition.

Sports analytics & media
Track player movements, annotate game events, and generate highlight packages automatically.

Healthcare
Annotate medical procedure videos for training, diagnostics support, and computer vision-assisted surgery.

Video annotation for AI
Video annotation is the process of creating metadata for video clips by tagging objects, actions, and events on a frame-by-frame basis. This data is essential for training computer vision models so they can interpret moving images and make accurate predictions in real-world scenarios.
Professional video annotation plays a critical role in computer vision – the area of AI that teaches machines to understand the visual world. By using expertly annotated videos, models can detect and classify objects, track movement, and respond to dynamic environments with enterprise-grade accuracy.
Further annotation services
Expand your AI model development with our diverse set of annotation services.
Data annotation
Flexible labeling support across images, videos, audio, and text to deliver precise training data at scale.
Image annotation
Bounding boxes, polygons, segmentation, and classification to power computer vision and object detection models.
Audio annotation
Speaker identification, acoustic event labeling, and emotion tagging for voice and sound datasets.
Text annotation
Domain-specific text enrichment including classification, entity tagging, sentiment analysis, and intent detection.
